Tell us about yourself and we will get back to you as soon as we can.
* Required, because we need to know how to get back to you.
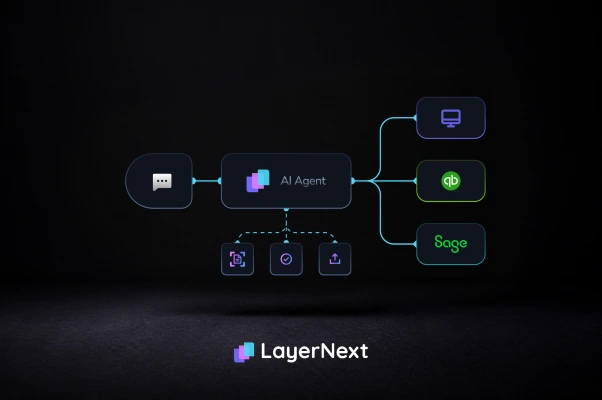
Most AP tools capture invoice data. LayerNext agents complete the workflow: validate, match, post to your ERP, reconcile. No API required. Your team approves every step.
SAP automation tools fall into three categories: native SAP, third-party RPA, and AI agents. Here is what each costs, where each fails, and which fits 2026.
Most AP automation stops at invoice capture. LayerNext completes the workflow inside legacy and desktop ERPs, with human approval at every step.
Compare the 6 best AP automation software for 2026. See how LayerNext, Tipalti, Bill, Stampli, Ramp, and Vic.ai stack up on legacy ERPs.
W-2 vs. W-4: What’s the difference? Learn when to fill out a W-4, how to read your W-2, and key deadlines for employees and employers in our comprehensive guide.
Master IRS Form 8832: The Entity Classification Election. Learn how LLCs can override default tax statuses, meet IRS deadlines, and avoid the 60-month lock-in rule.
Manual bookkeeping costs small businesses 15 hours a month. An AI CFO automates it in real time, starting at $79/month. No bookkeeper required.
Spot the 6 clearest signs your business has outgrown QuickBooks. Learn why adding more apps makes it worse and how an AI Finance OS fills the gap without an ERP.
Marketing agencies lose hours monthly on QuickBooks cleanup. This guide covers retainer billing, media passthrough, project P&L, and AI fixes for each.
Shopify-QuickBooks connector has been broken since January 2026. Orders not syncing, customer data vanishing, COGS discrepancies. Here is what happened and how to fix your Shopify bookkeeping permanently.
Roofing bookkeeping breaks during storm season. Learn how to track ACV, RCV, and supplement payments in QuickBooks, and automate the process with LayerNext.





.webp)







